There have been ground breaking changes in the field of AI, where many a new algorithms and models are being introduced and worked up. The pace that we have been moving at, is sure to bring many more rapid developments in various industries with AI as major change maker. Here we are going to talk about the incredible evolution journey of NLP Models.
While Google’s BERT and Transformer did set some amazing records, Facebook’s RoBERTa, which is based on BERT, surpassed many previous records and then Microsoft’s MT-DNN exceeds the benchmarks set by Google’s BERT almost of nine NLP tasks out of eleven.
Google implemented two major strategies with BERT – Mask Language Model, where an amount of words was masked, kept hidden in the input and the BERT was to predict the hidden word. Refer the below example for better understanding.
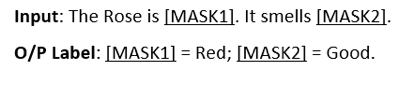
Referring to the above example, the masked words were kept hidden as part of training and model was to anticipate the words. For BERT, it was essential to understand the context of the sentence based on the unmasked words and predict the masked one, failing to produce expected words like Red and Good, would be a result of failed training techniques.
Moving ahead, Next Sentence Prediction (NSP) was the second technique used with BERT, where BERT learned to establish a relationship between various sentences.
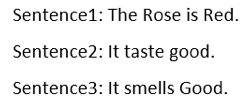
Major task for NSP was to choose next sentence, based on the context of current sentence, to make proper pairs of sentences. Referring to the above sentences, BERT would have to choose the Sentence3 in order to complete the Sentence1 as its successor. Choosing Sentence2 instead of Sentece3 would result in failed training of the model. Both of the above techniques were used in training the BERT.
Real Life examples of BERT can be seen with Gmail app, where replies are being suggested according to the mail, or when you start typing a simple sentence, further words to complete the sentence can be seen in Light Grey Fond.
Everything we have today is better than yesterday, but the tomorrow will demand many improvisations, “There’s always some room for Improvement”.
When Google broke the records with BERT, it was exceptional but then Facebook decided to implement the same model of BERT, but with a slight change. The changes here were improved methods for training, with massively added amounts of data and a whole lot more of computation.
What Facebook did was, simple carry forward the Language Masking Strategy of BERT but decided to replace the Next Sentence Prediction Strategy with Dynamic Masking.
When Google fed its model, BERT, with massive amount of data with masked words, it was Static Masking, has it happened only at time of insertion. But what Facebook did was, tried to avoid masking same word multiple times and so training data was repeated 10 times and every next time, the masked word would be different, meaning the sentence would be same but the words masked would be different and this made RoBERTa quite exceptional.
Parameters, a very important part of training data, has to be accurate and useful for the model and must be in vast amount for the model to learn every possible scenario. NVIDIA, exceeded every past record for maximum parameters when they trained world’s largest Language Model named as Megatron, which is based on Google’s Transformer, with 8.3 BILLION Parameters. Amazingly, NVIDIA trained the model in 53 minutes and happily made it accessible for other major players like Microsoft and Facebook, to play with its State-of-the-Art Futuristic Language Understanding Model.
BUT BUT BUT, what DistilBERT did was, stood up with almost matching results as BERT but with using almost half the number of parameters. DistilBERT meaning Distillated-BERT, released by Hugging Face uses only 66 million parameters while BERT base uses 110 million parameters.
Along with Toyota Technological Institute, Google released a Lite version of BERT, ALBERT. While BERT xLarge uses 1.27 billion parameters, ALBERT xLarge uses only of 59 million parameters, now that’s reducing parameters to almost half. Smaller and Lighter compared to BERT, ALBERT might be BERT’s successor. Sharing Parameters is one of the most impressive strategy implemented with ALBERT, which works on hidden level of model. With Parameters Sharing, loss of accuracy happens but also reduces the number of parameters required.
Google, with Toyota brought out ALBERT, and as described above, it uses less parameters and implements a strategy to convert the words into numeric one-hot vector, which are later passed into an embedding space. But it is essential for embedding space to have same dimension as of the hidden layer and this was surpassed when ALBERT team factorised the embedding, meaning the earlier created word vectors were first projected into smaller dimension space and then pushed into higher one with the same dimension.
Next is probably to harness the Language Intelligence that made English Language quite interesting for machines to understand and learn, to be implemented with various languages. Every language has its own roots and varies a lot with multiple factors, but possibility is to train next languages just as it was done with English Language.
Many improvements are being made with added computation or by increasing data, but one factor that will be considered to be ground breaking in the field of AI is when models are efficiently being trained and improved with smaller amount of data and less computation. To talk to our NLP expert on how to use the NLP Models for your business contact us





